Building an automated solution for index and cluster management for Elasticsearch/AWS OpenSearch
29 January 2025
In today’s data-driven world, quick and reliable access to data is key to making informed decisions. That's why more companies are turning to tools like Elasticsearch and AWS OpenSearch to power their search and analytics capabilities. These tools make it easy to deploy, operate and scale search systems in the cloud, enabling use cases like log analysis, application monitoring and website search.
How Payment Data Store (PDS) leverages Elasticsearch and AWS OpenSearch
At J.P. Morgan Payments, we combine Treasury Services, Trade & Working Capital, and Merchant Services capabilities to help clients pay customers or employees, in different currencies, around the world. We process nearly US$10 trillion payments daily, operating in over 160 countries and over 120 currencies, and are ranked #1 in USD payments volume.1
As part of the Payment Data Store (PDS), the central warehouse of all payments data within J.P. Morgan Payments, we are responsible for securely processing, storing and facilitating the retrieval of payments data for real-time analytics and business insights. As the system of record (SOR) for payments data, one of the key functionalities for PDS is to ensure high availability and accuracy of data to enable informed business decisions, as well as to facilitate accurate Operational, Compliance and Regulatory (OCR) reporting. Inaccurate data reporting can have disastrous consequences such as financial losses, reputational damage or compliance issues.
To enable our internal users to have quick access to our payments data and to facilitate OCR reporting, we make use of AWS OpenSearch as the primary document store across the core Payments organization, leveraging its ability to handle large-scale, real-time data processing with low-latency search, which at our scale are crucial capabilities to ensure operational accuracy and performance. More and more organizations are looking for solutions that can make observability fast, cost-effective and easily accessible. This is where AWS OpenSearch fits the bill. AWS OpenSearch is an open-source search and analytics engine, which makes it easy to deploy, operate and scale AWS OpenSearch clusters in the AWS Cloud, allowing you to run use cases such as log analytics, real-time application monitoring and clickstream analysis.
The need for efficient index and cluster management
Efficiently managing AWS OpenSearch/Elasticsearch indices and cluster resources can lead to significant improvements in performance, scalability and reliability—all of which directly impact a company's bottom line. However, the industry lacks native and well-documented solutions to automate these important operational tasks.
At J.P. Morgan Payments, we found that manually managing our AWS OpenSearch/Elasticsearch environment was a slow and error-prone process. Without automation, tasks like creating index templates, configuring lifecycle policies and updating access permissions became time-consuming and prone to human error. We also struggled to maintain version control and an audit trail of changes.
To solve these challenges, we evaluated various tools that could help automate our AWS OpenSearch cluster management. One option was ES Beyonder, a library that allows you to automatically perform operations but is native to Elasticsearch and doesn’t allow you to extend the framework to AWS OpenSearch Service. Another option was the AWS OpenSearch Terraform Provider, which is used to interact with the resources supported by AWS OpenSearch but that was unfortunately not available within the JPMC environment. We ultimately chose to use a Java-based library called Evolution, which can provide native support for automating AWS OpenSearch cluster operations.
The choice of Java as a programming language for building the framework was a natural one, as it is the language of choice not just within J.P. Morgan Payments, but across the entire firm. Java's robust capabilities, combined with its extensive ecosystem and community support, make it an ideal fit for high-volume processing applications across multiple industries.
Evolution is largely inspired by the popular Flyway tool, and it follows a set of conventions that make it well-suited for building cloud-native solutions. Crucially, Evolution uses an "optimistic locking" mechanism to ensure only one application instance can execute the management scripts at a time. This helps provide a reliable audit trail of all changes made to our AWS OpenSearch environment.
At JPMC, we have integrated Evolution as part of our CICD pipeline. Evolution scripts help us automate the creation, update and management of AWS OpenSearch mappings, templates and aliases. Out of scope of this post is the reindexing strategy, which is another important area to think through when, for instance, updating index templates.
Use cases and features
Use cases
- Automation of index and cluster management operations including (but not limited to):
- Index management operations
- Index template operations
- Alias operations
- Index state management
- Data stream operations
Features
- Allows for version control of scripts.
- Maintains Audit trail of all executed scripts.
- Runs on Elasticsearch version 7.5.x - 8.13.x.
- Runs on AWS OpenSearch version 1.x - 2.x.
- Highly Configurable
- Placeholder substitution in migration scripts
- Supports Microservices / multiple parallel running instances via logical database locks.
- Supports line comments in migration files
How to use
The framework (written in Java) can be implemented in a variety of ways including, but not limited to, deploying it as a standalone Java application or as containerized application in any cloud service provider or via a serverless compute service.
To leverage Evolution in your project, you need to follow the below steps:
1. Add elasticsearch-evolution dependency
1.1. To begin with, you need to add the latest version of Evolution core library as a Maven dependency and also add AWS SDK related dependencies.
<dependency>
<groupId>com.senacor.elasticsearch.evolution</groupId>
<artifactId>elasticsearch-evolution-core</artifactId>
<version>0.6.0</version>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>auth</artifactId>
<version>2.17.243</version>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>core</artifactId>
<version>2.17.243</version>
</dependency>
2. Create Evolution bean along with AWS Interceptor, which implements HttpRequestInterceptor.
3. Interceptors are open-ended mechanisms in which the SDK calls code that you write to inject behavior into the request/response lifecycle. The function of AWS Interceptor is to hook into the execution of API requests and create an AWS-signed request stamped with proper IAM roles.
4. Leverage the AwsRequestSigningApacheInterceptor.java code to create your own implementation to sign all the requests made to AWS OpenSearch.
5. Next, and crucially, create your own AWS OpenSearch Client to manage automatic creation of index, mappings, templates and aliases.
6. The default Elasticsearch Client that comes bundled in as part of the maven dependency cannot be leveraged to make PUT calls to AWS OpenSearch cluster. Hence, you need to bypass the default Rest Client instance.
7. Below is a sample REST Client implementation that we created for our project:
private RestClient getElasticsearchEvolutionRestClient() {
return RestClient.builder(getHttpHost())
.setRequestConfigCallback(rccb -> rccb.setConnectionRequestTimeout(awsOpenSearchMigratorConfig.getConnectionRequestTimeoutMs())
.setConnectTimeout(awsOpenSearchMigratorConfig.getConnectionTimeoutMs())
.setSocketTimeout(awsOpenSearchMigratorConfig.getSocketTimeoutMs()))
.setFailureListener(new LoggingFailureListener())
.setHttpClientConfigCallback(hacb -> hacb.addInterceptorLast(getAwsRequestSigningInterceptor())
.setMaxConnTotal(awsOpenSearchMigratorConfig.getTotalMaxConnections())
.setMaxConnPerRoute(awsOpenSearchMigratorConfig.getMaxConnectionsPerRoute()))
.build();
}
8. As the last step, you need to use the Evolution Bean to call your migrate method which is responsible for initiating the migration of the scripts defined either using classpath or filepath.
public void executeOpensearchScripts() {
ElasticsearchEvolution elasticsearchEvolution = ElasticsearchEvolution.configure()
.setEnabled(true) // true or false
.setLocations(Arrays.asList("classpath:opensearch_migration/base", "classpath:opensearch_migration/dev")) // List of all locations where scripts are located.
.setHistoryIndex("opensearch_changelog") // Tracker index to store history of scripts executed.
.setValidateOnMigrate(false) // true or false
.setOutOfOrder(true) // true or false
.setPlaceholders(Collections.singletonMap("env","dev")) // list of placeholders which will get replaced in the script during execution.
.load(getElasticsearchEvolutionRestClient());
elasticsearchEvolution.migrate();
}
Migration script format
An Evolution migration script represents a REST call to the AWS OpenSearch/Elasticsearch API (e.g., PUT /_template/my_template), where you define index patterns, settings and mappings in JSON format. Evolution interprets these scripts, manages their versioning and ensures ordered execution.
Here is an example:
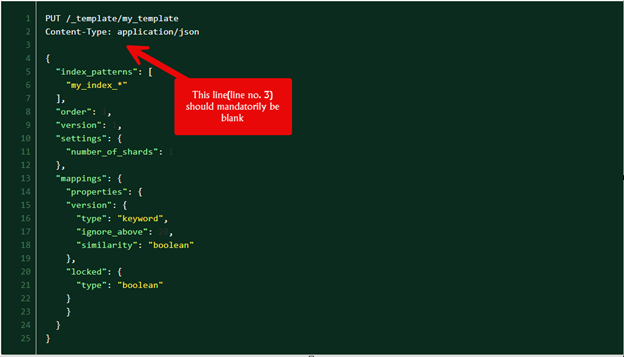
The first line defines the HTTP method PUT and the relative path to the AWS OpenSearch/Elasticsearch endpoint /_template/my_template to create a new mapping template, followed by a HTTP header Content-Type: application/json.
This must be followed by a blank line, which the HTTP body is then defined.
The pattern is strongly oriented in ordinary HTTP requests and consist of four parts:
- The HTTP method (required): Supported HTTP methods are GET, HEAD, POST, PUT, DELETE, OPTIONS and PATCH. The first non-comment line must always start with an HTTP method.
- Path to the AWS OpenSearch/Elasticsearch endpoint (required): The path is separated by a blank from the HTTP method. You can provide any query parameters like this: /my_index_1/_doc/1?refresh=true&op_type=create .
- HTTP header(s) (optional): All non-comment lines after the HTTP method line will be interpreted as HTTP headers. Header name and content are separated by a colon.
- HTTP body (optional): The HTTP body is separated by a blank line and can contain any content you want to send to AWS Opensearch/Elasticsearch.
Evolution also supports line-comments in its migration scripts. Every line starting with # or // will be interpreted as a comment-line. Comment-lines are not sent to AWS Opensearch/Elasticsearch, as they will be filtered by Evolution.
Migration script file naming convention
The filename must follow a pattern:
- Start with esMigrationPrefix, which is by default “V” or the value that has been configured using the configuration option esMigrationPrefix listed above.
- A version number, which must be numeric and can be structured by separating the version parts with dot(.)
- The versionDescriptionSeparator: __ (double underscore symbol).
- A description, which can be any text your filesystem supports.
- Finally, esMigrationSuffixes, which is by default “.http” and is configurable and case insensitive.
Here is an example filename: V1.0__my-description.http
As with flyway, Evolution uses the version for ordering your scripts and enforces strict ordered execution of your scripts, by default. Evolution interprets the version parts as integers, so each version part must be between 1 (inclusive) and 2,147,483,647 (inclusive).
Out-of-order execution is supported, but disabled by default. When enabled, out-of-order property instructs Evolution to scan through all the scripts (as opposed to starting with the script with maximum version number) and execute them.
In case the script was successfully executed before and has status as "Success," Evolution skips those scripts. If the previously executed script had failed due to any issues, then Evolution will re-execute those scripts along with any newly added scripts.
Here is an example which indicates the ordering: 1.0.1 < 1.1 < 1.2.1 < (2.0.0 == 2). In this example, version 1.0.1 is the smallest version and is executed first, after that version 1.1, 1.2.1 and in the end 2. 2 is the same as 2.0 or 2.0.0, so trailing zeros will be trimmed.
Directory structure for scripts
We recommend structuring your migration scripts following a directory-based strategy, inspired by Kubernetes kustomize folder strategy, which maintains a base folder to define all common properties (applicable across all the environments) and allows for environment-specific properties to be defined under different overlays folder (e.g., dev/test/prod). You can find the details on the setup and naming conventions in the GitHub repository.
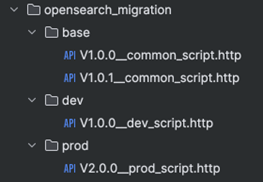
For the above approach to work properly, you need to set the locations property of the Evolution bean per your environment and set out-of-order execution to true. For instance, for the dev environment, this property will look like the below. This ensures that scripts present in the base folder and dev folder will get executed.
locations: classpath:opensearch_migration/base, classpath:opensearch_migration/dev
The above proposed structure is not binding, and you are free to choose any other directory structure that suits your organizational use cases.
Conclusion
Throughout our work, we took an in-depth look into the capabilities and offerings of the Evolution library, and this helped us establish a well-defined and proven approach to automate the index and management operations of an AWS OpenSearch/Elasticsearch cluster within JPMC.
This approach yielded faster deployment time, better version control, reduced undifferentiated operational overhead and enabled a more reliable index management approach across our clusters and environments.
To go further with the Evolution library
Please visit the documentation.
1. J.P. Morgan proprietary data, 2023